This is one of the common questions we get when prospects come looking for data replication tools. It’s more a question of Integration design patterns than of product implements.
Let’s get started with what an ESB is – Enterprise Service Bus. This is an integration design pattern where messages are passed so that one or more Message Listeners can listen and consume the message – store and forward. These messages—like, say, emails—have a header (from and to), a payload (the message), and perhaps attachments. Based on the ESB, there might be some limitation on payload and attachments sizes.
The Flow is like This:
App produces message -> ESB receives message (in a queue) -> Based on Routing rules, ESB routes message -> Listener Consumes Message -> Likely maps/translates data -> Saves / forwards to another app/queue -> confirm message is received -> ESB tags and stores message as processed.
Notice the ones in “bold”. These are places where data flow can “choke” or “build up” if there is a high flow of large data sets.
Now look at Data Replication: you have a source of data, be it a database (common) or a Cloud Application (like Salesforce). In data replication, you would require a complete backup of both schema and data changes. The application is expected to identify schema changes and update to target (without the need for remapping), so interpreting schema changes and having the ability to adjust target schema changes becomes important. The ability to process a large number of rows is necessary. One of the common ways that most databases replicate is using their transactional logs (when you look under the hood of master–slave replication). When you have disparate applications like Salesforce and Oracle, then you have to rely on query-> extract -> interpret change -> check for target source duplicate -> load on another system.
Ok, so let’s now look at why ESB-based apps might not be the right choice:
- ESB requires store and forward, which might not be necessary for data replication. While you can debate that it will work (yes you can make it work), it will be slow and overly complicated.
- ESB in general is considered to have the higher overhead of operation management and requires higher uptime as it’s mostly used for distributed app integration. Replication usually is run on batch (or scheduled time) or, in the case of master–slave, a lot more real time than what ESBs are designed for.
- Managing schema changes often requires ESBs to remap some of the message flows. Some of our clients really dislike this, in that not only do they have to track source and target schemas, but also often trigger a “Change Management” request up the IT chain, which can take weeks or months to get over. Data Replication tools usually automatically adjust target schemas.
When you look at the Integration Tools market, the industry has segmented itself, with one group going the ESB or Message queue route (which is slowly evolving into API-based integration) and that of data replication.
So let us see some of the common integration apps and how do they fit in:
MuleSoft- A leader in ESB-based integration and does quite well in Service-oriented architecture and does well in integrating apps like SAP and others. They are also introducing API management.
Kafka- Open-source Messaging platform, very popular in high-volume messaging, especially with IoT and big data. It requires smaller messages size.
GoldenGate (by Oracle) – a leader in data replication between different databases. Does not yet have Cloud application data replication.
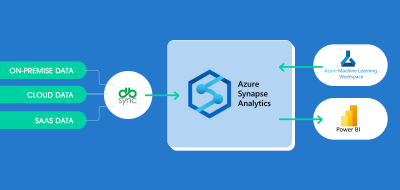
DBSync – Cloud Data Replication uses direct replication technique while iPaaS Cloud Workflow is more a store and forward.
There are many more; perhaps a good place to look is Gartner’s Data Integration and Gartner’s Integration-as-a-Service magic Quadrants to see which are leading the pack.