What data engineers look for in data replication software [A Buyer’s Guide]

Choosing the right data replication software is no longer just about checking off a list of features you found on a blog. It’s about finding a tool that won’t give you a headache at 2 a.m. when a pipeline breaks. Data teams need solutions that not only move data reliably but also align with complex architectural setups and can scale to adapt with evolving workloads.
This guide isn’t your typical marketing spiel. It’s a blueprint for the kind of tough questions you should be asking. We’ll skip the buzzwords and dive into the technical details and real-world problems that truly matter.
Why Move Beyond the Checklist?
Most blogs offer a high-level comparisons of replication tools, useful for early research, but not enough for real decision-making. What teams truly need to know is: How will this software perform in my architecture, at my scale, and in my day-to-day operational reality?
Before you even look at features, you need to think about how a tool fits into your big picture. It’s all about the fundamental choices that lay the groundwork for a solid pipeline. The first decision is a big one: How is the data going to move?
Part 1: The architectural blueprint of your replication strategy
1. Trade-off between Async vs. Sync replication:
Choosing between synchronous and asynchronous replication boils down to a fundamental trade-off.
In synchronous replication, a transaction is only considered done on the primary system once it’s also written to the replica. This is a “commit-and-wait” approach that ensures consistency and zero data loss but adds latency and is slow. Ideal for mission-critical tasks like financial transactions.
Opting for asynchronous replication prioritizes sheer speed. The primary system executes a transaction and then immediately signals completion, the data is subsequently relayed to the replica. This technique yields low latency and significantly greater performance, making it the de facto standard for high-volume and fast-moving applications like real-time analytics, BI, etc. The trade-off is however, is that if the primary system fails, the data not yet replicated risks being lost. Learn more about data replication strategies.
2. Master-Slave vs. Multi-Master Replication
In a master-slave system, your architecture is built on a single point of command. A primary database acts as the sole authority for all changes, with its replicas serving as read-only followers. This design offers a simple, reliable path for applications dominated by read requests.
The multi-master strategy is different because every database is a peer, capable of accepting writes. This provides high availability and low latency for global applications. But this flexibility introduces the complexity of resolving data conflicts that arise when multiple sources change the same data.
3. How well it scales horizontally and vertically
For a data system, growth isn’t a one-size-fits-all problem. Sometimes you need to scale up (or scale vertically). This means ramping up a single machine by adding more CPU, memory, or storage. It’s the simplest fix, like giving your current workhorse a massive performance boost.
But when that single machine hits its limit, you must scale out, or horizontally. This means distributing your workload across an array of machines. It’s like creating a collective of specialists, all working in unison to tackle an enormous task.
A smart buyer knows the best tools offer both. Vertical scaling is a quick, simple path for immediate needs, while horizontal scaling is the only viable route for managing large, unpredictable data growth and ensuring continuous availability across a distributed system.
Part 2: The engineer’s toolkit
This is where we get into the nuts and bolts, the things that make an engineer’s day-to-day a breeze or a nightmare.
4. How it handles incremental vs. full replication
Data replication offers a fundamental duality in its approach to moving information. The first strategy, full replication, is a meticulous undertaking that duplicates the entire dataset from source to destination. It serves as a comprehensive blueprint for an initial setup or a complete archival.
The alternative is incremental replication. This method pinpoints and transfers only the alterations since the last synchronization. This selective process is a boon for efficiency, significantly lowering system load and keeping your information current without the need for constant, exhaustive transfers.
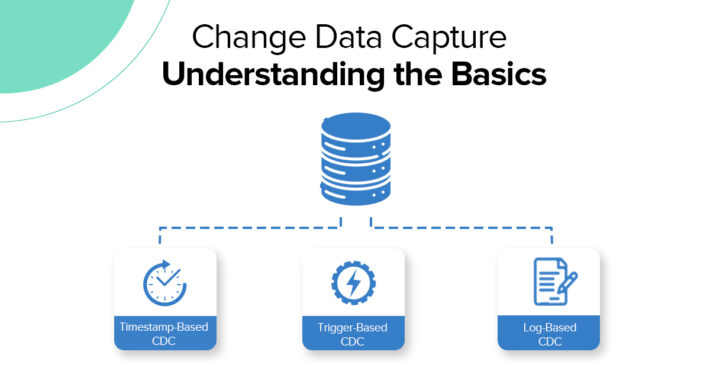
5. How efficient is the change data capture capability?
Change Data Capture (CDC) is a must-have feature for any modern data replication tool. It keeps analytics dashboards and operational systems perfectly in sync with minimal latency and without adding unnecessary load on your systems and network
Go for tools that use log-based CDC methods as it’s the gold standard for high performance and low impact on the source. Other like trigger-based (heavy load and hard to maintain) and query-based CDC (slow and lacks accuracy) are generally considered outdated or inefficient.
6. Does it offer in-flight transformation:
Why wait to scrub data once it has landed in your warehouse? The latest replication platforms allow you to filter or mask sensitive information, like PII, or even adjust data types while the data is still in-flight. This kind of proactive scrubbing save guards your time and prevents numerous compliance and security risks down the line. By tackling these tasks upfront, it lets you keep critical information accurate and consistent.
 Sync data from Dynamics 365 to Oracle
Sync data from Dynamics 365 to Oracle
 Sync data from Dynamics 365 to AWS Redshift
Sync data from Dynamics 365 to AWS Redshift
 Sync data from Dynamics 365 to AWS S3
Sync data from Dynamics 365 to AWS S3
Part 3: The operational reality
This is what separates a good tool from a great one. How does it behave when things go wrong?
7. How resilient it is to failures, schema changes, and performance bottlenecks
When buying a data replication tool, consider its resilience to handle common issues. Look for automatic failure handling with alerting to ensure data pipelines recover from network issues without manual intervention.
The tool must also include automated schema change management to prevent pipeline breaks when your database structure evolves. Finally, it should offer intelligent performance optimization and scaling to handle increasing data volumes and maintain smooth data flow without slowdowns.
8. What security measures are available for data compliance
For a data replication tool, security and compliance are non-negotiable. The product you choose must offer robust, built-in measures to protect sensitive data.
Look for solutions that provide end-to-end encryption (both in-transit and at-rest), role-based access control (RBAC) to limit user permissions, and automatic audit trails for compliance. These features ensure data integrity and help your business meet industry-specific regulations like GDPR or HIPAA, safeguarding your brand against costly breaches.
9. Where it stands on ease of use and support
Ease of use is crucial for any data replication tool. A good platform should feature a clean, intuitive interface with pre-built connectors and templates that allow users to set up workflows without heavy coding. This simplicity saves time, reduces errors, and enables teams to focus on delivering value.
Equally important is robust customer support. The provider should be a partner, offering reliable assistance through clear communication and access to technical experts. A comprehensive knowledge base and proactive monitoring further empower teams to maintain smooth data flow and resolve issues quickly.
10. Observability: Seeing Inside Your Pipeline
You can’t fix what you can’t see and so here’s some key metrics to to look after:
- Replication Lag: This is probably the single most important metric. It tells you how far behind your target system is from the source. A rising lag is a clear warning sign.
- Throughput: How much data are you actually able to move and how much it deters from the business demand?
- Error Rates: How often are jobs failing? A high error rate points to a bigger issue.
- Resource Utilization: How much CPU and memory does the tool utilize?
- Proactive Alerts: The best tools will let you set up alerts so you get a ping before a small problem becomes a five-alarm fire.
A vendor vetting checklist to help you cut through the marketing
Here are some questions to ask your vendor during a demo or evaluation discussion. These questions will help you cut through the marketing and sales language so you can directly get to the technical details that really matter for your architecture and team.
- Is asynchronous vs. synchronous replication configurable per job? This lets you apply the right replication strategy to different data pipelines based on their specific needs for latency and consistency.
- How are conflicts handled in multi-master setups? You need to understand the tool’s built-in rules for resolving conflicts to ensure data integrity without manual intervention.
- What’s the process for scaling up/out as data volumes grow? Your vendor should have a clear, documented process for scaling so your system can handle future growth without major disruptions.
- How does the system recover from failures or schema changes? A resilient tool will have automated mechanisms to resume replication and adapt to schema changes, preventing pipeline breaks.
- What compliance certifications does the platform meet? This is crucial for ensuring the platform has the necessary built-in security and governance features for your industry.
- Can non-developers build and manage data pipelines? The platform’s ease of use directly impacts productivity, empowering more team members to work with data.
- Does the tool support real-time alerts and dashboards? Observability is key for a production environment, so you need to know how the tool helps you proactively monitor its health.
- How is support delivered – email, phone, chat, documentation, forums? A good support model is a partnership, so you should understand what resources are available when you need help.
| Feature/Capability | Why It Matters | What to Ask Your Vendor | With DBSync |
| Incremental vs. Full Replication | Balances performance with completeness | Can you switch between both easily? | Yes |
| Async vs. Sync Replication | Lets you tune for speed or safety | Are both options available? | Yes |
| Master-Slave vs. Multi-Master | Adapts to team or reliability needs | How is conflict handled? | Conflict resolution built-in |
| Horizontal & Vertical Scalability | Supports your business growth | How quickly can capacity expand? | Cloud-native scaling |
| Resilience & Auto-Failover | Ensures uptime and smooth recovery | How does the tool handle outages? | Automated retries, alerts |
| Multi-Source Support | Centralizes data from all key systems | What connectors are pre-built? | 30+ connectors and APIs |
| Security & Compliance | Keeps data safe and regulation-ready | Is there encryption and audit trails? | End-to-end encryption |
| Low-Code Setup | Makes onboarding quick and simple | Can non-tech users build pipelines? | Drag-and-drop workflows |
| Real-Time Monitoring & Alerts | Detects issues early and keeps pipelines healthy | Are there dashboards and notifications? | Yes |
Conclusion — Architecture Over Features
The right replication platform isn’t the one with the longest feature list, it’s the one that aligns with your technical blueprint. By focusing on architecture, CDC mechanics, observability, and security, you’ll build replication pipelines that can scale with your business and adapt to new demands.
If you’re ready to modernize your data movement strategy, DBSync offers real-time, secure, and flexible data replication software designed to meet the needs of modern enterprises.
FAQs
What is the difference between full and incremental replication?
Full replication copies all your data at once; incremental replication just moves new or changed data since the last run, saving time and resources.
How does Change Data Capture (CDC) improve replication speed?
CDC reduces unnecessary copying by tracking and syncing only what’s changed, allowing real-time data movement without bogging down your database.
Why is security crucial for data replication?
Data can contain sensitive or regulated information. Encryption, role-based access, activity logs, and compliance features minimize risk and protect your business.
What should I ask a vendor about resilience and scalability?
Ask about automatic failure recovery, horizontal scaling in the cloud, support for version/schema changes, and integration with monitoring tools.