Beyond Data Lake vs. Data Warehouse: The Path to Integration and Convergence

Introduction: Why This Debate Matters More Than Ever
If you try searching for “Data Lake vs. Data Warehouse” online, you will find numerous explanations like these: “Lakes hold raw data; warehouses hold structured data.” Are these helpful? Yes, to build a basic understanding. But can this be used for making an informed decision? Not really.
The conversation of data lake vs. data warehouse is far more nuanced. Today’s world is digital, and businesses employ numerous systems to get their work done, be it SaaS applications, CRMs, ERPs, or financial systems. With all these systems in place, the real question is not in understanding the differences. Rather, it is in understanding about the approach that will enable unify this scattered data into a single source of truth that drives agility and smarter decisions
In DBSync, where our expertise lies in tying applications together, integrating data flows, and simplifying integrations, we witness these situations quite often. A company drowning in raw, unstructured data or paralysed by inflexible reporting pipelines ultimately loses one of the most precious things that matters most in today’s time: momentum.
Start Your 14-Day Free Trial
- Pre-built connectors and ready-made integration templates
- Real-time and bi-directional data sync
- Self-healing automation - zero babysitting
In this blog, we explore the debate on data lake vs. data warehouse from a different angle: how choosing between a data lake and a data warehouse affects integration, agility, governance, and most importantly, the readiness for tomorrow. We will also discuss how AI/ML and cloud-native platforms are leading this debate from divergence towards convergence.
From Storage to Strategy: How Lakes and Warehouses Enable Integration
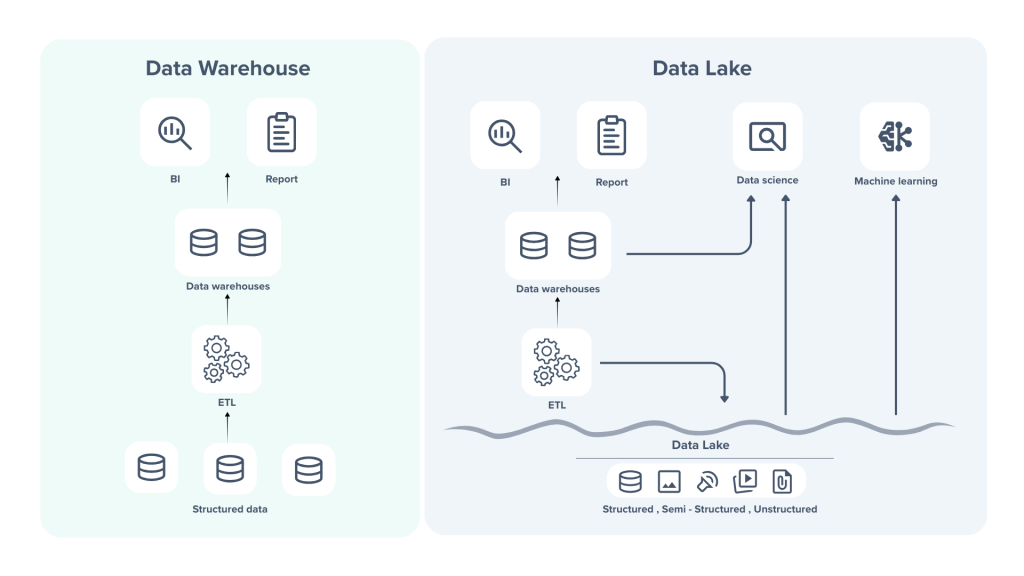
One of the most limiting assumptions decision-makers make is treating lakes and warehouses purely as storage solutions. In reality, they are not just the storage arms but the anchors of any organisational integration strategy.
Imagine your business as an airport. Here,
- A data lake is like the tarmac. It can accommodate any flight, be it large or small, passenger or cargo, from any of the airline operators. This is cost-effective and flexible but is a mess unless you manage it properly.
- Whereas a data warehouse is like the terminal. Here, everything is structured, labelled, and organised for a pleasant passenger experience. It helps move passengers and luggage properly but only supports specific routes (schemas).
Here, what really matters is not just which option stores data better but also which one supports or limits the way your applications and systems integrate. Without integration, both lakes and warehouses become isolated silos which are powerful on their own but disconnected from day-to-day business workflows that depend on them.
For instance:
- A data lake lets Salesforce logs, IoT streams, and Microsoft Dynamics 365 journal entries all coexist together in their original form. It doesn’t enforce storing data into a single, rigid schema. This flexibility is one of the biggest advantages for teams that want to experiment quickly with AI, anomaly detection, or cross-domain analytics. But here, without the proper integration pipelines feeding the right data in and pulling insights back out, the lake risks becoming just another dumping ground.
- On the other hand, a warehouse gives business analysts and finance leaders the confidence to run their quarter-end reports knowing that every row, every entry, and every transaction follows a consistent schema and governance framework. But if the data feeding into the warehouse does not automatically integrate from systems like NetSuite, ServiceNow, or Shopify, even the most reliable warehouse can end up running on stale or incomplete data.
In a nutshell, data lakes offer flexibility and inclusivity, whereas data warehouses offer consistency and trust, and integration ensures that both deliver value by keeping data updated, connected, and business-ready.
The Real Costs of Choosing Wrong: Lost Agility
Decision makers often zero in on factors such as the cost per terabyte or the query performance while comparing lakes and warehouses. But the real game changer isn’t only the financial angle; rather, it is strategic.
When you over-rely on a warehouse, then you would require remodelling for every new data source that is added to the system. Imagine delaying a new product launch just because your analytics team spent three months building schemas for Shopify sales data. It leads to the loss of momentum.
On the flip side, when you over-rely on one lake, it leads to “data swamps”. You could end up spending more than half the analytical team’s time cleaning raw data rather than deriving meaningful insights. Decisions are delayed, and opportunities are foregone. Again, there is a loss of momentum.
In today’s fast-moving markets, where customer behaviour shifts weekly and competitors innovate daily, momentum is everything. The wrong choice or an imbalance could slow down decision-making and reduce speed.
 Sync data from Dynamics 365 to Azure Data Lake Gen2
Sync data from Business Central to Azure Data Lake Gen2
Sync data from Dynamics 365 to Azure Data Lake Gen2
Sync data from Business Central to Azure Data Lake Gen2
 Sync data from MySQL to Azure Data Lake Gen2
Sync data from MySQL to Azure Data Lake Gen2
Why does governance matter? Because it creates trust.
Another overlooked aspect of the data lake vs. data warehouse debate is governance.
Data warehouses come with strong governance baked in. The data stored is structured, controlled, and can be easily audited. This makes data warehouses an ideal choice for industries which demand strong compliance, such as banking, healthcare, insurance, etc.
On the other hand, data lakes can accommodate data in various shapes and forms. They enable experimentation but can also potentially expose organisations to risk without sensible controls in the form of governance (think GDPR, HIPAA, or SOX compliance).
The aspect of governance goes beyond compliance; it is about creating trust in the data you provide and rely on. And if there is no trust, integration becomes meaningless. Imagine if the number on the sales dashboard doesn’t add up to the finance figure. What happens? You lose trust.
Decision Framework: Lake, Warehouse, or Both?
Let us try to understand using a metaphor. Consider your data ecosystem as a contemporary city:
- The data lake is the industrial area; it is large and unstructured and is the key area for experimentation and scale.
- The data warehouse is the residential zone, neat, standardised, and optimised for daily operations.
- The emerging lakehouse is the smart city hub, where industry and residence connect seamlessly. It offers the flexibility of the industrial area along with the governance and order of the residential zone.
Just as a smart city amalgamates power, transportation, and communication into a cohesive system, a lakehouse unifies the expansive scalability of data lakes with the organised reliability of data warehouses, thereby providing businesses with an optimal blend of both realms. The choice, therefore, isn’t a lake or warehouse but a combination or convergence that is suitable for your current business trajectory.
So, rather than viewing the discussion on data lake vs. data warehouse as an either-or situation, it would be a better choice if we saw it as a journey towards maturity.
Navigating the right choice depends on where your business is on its data journey. To simplify the decision-making process, here is a quick framework that aligns your business stage with the ideal data solution.
| Business Stage | Recommended Solution | Why |
| Fast-moving | Data Lake | Your primary need is flexibility to experiment with new data sources and quickly explore opportunities. |
| Scaling | Data Warehouse | As you grow, the focus shifts to standardization and reliable reporting, which a warehouse provides. |
| Mature Enterprise | A Hybrid Model (Lakehouse/Data Fabric) | You need the raw flexibility of a data lake for innovation and the structured reliability of a data warehouse for trusted reporting. |
- For Fast-Moving Businesses: Flexibility with Data Lakes
- Choosing a data lake is a better option. As you are exploring and introducing new SaaS applications in your ecosystem, you need a lake, even though you might not yet understand how you will exploit it.
- For example, a direct-to-consumer (D2C) startup is integrating clickstream data, Shopify orders, and social media sentiment in a data lake to support AI-powered customer insight.
- Scaling Up: Standardize with a Data Warehouse
- Implementing a data warehouse is a better option. With an established business, the question becomes standardisation. Executives and leadership want dashboards that they can rely on, auditors want clean audit trails, and finance needs uniform reporting. Warehouse helps you achieve that.
- For instance, a midsized manufacturer is transferring recurring supply chain and ERP data into a warehouse in pursuit of operational excellence.
- Maturity Stage: Balance with a Lakehouse
- Utilizing both elements is a smart choice. The lake serves as the primary landing zone, whereas the warehouse refines and curates what is essential. Collectively, they provide both flexibility and reliability.
- Increasingly, cloud-native platforms like Snowflake, Databricks Lakehouse, and Google BigQuery are eliminating boundaries, bringing forth the idea of the “lakehouse”, which is an integrated environment offering the scale of the lake along with the governance of the warehouse. While the idea is still evolving, the approach represents where most businesses are headed.
Why Data Lakes and Warehouses Work Better Together for AI/ML
One thing hardly talked about in this argument is how the game is transformed by AI and ML.
Machine learning loves diversity: clickstreams, sensors, transcriptions of phone calls, IoT logs, and image data that barely end up in a warehouse schema. And so, data lakes become the natural choice for AI development.
But there is a twist to this tale: the AI/ML models need trustworthy, structured data to validate insights and drive operational choices. This is where data warehouses come in.
Example:
- Data lake: Holds raw e-commerce browsing behaviour data, shopping cart abandonment, and heatmaps.
- Data warehouse: Stores customer information, purchase history and transaction data
- When you bring these two together, you come up with a powerful recommendation engine, one that anticipates what a customer might order next, and also makes sure that the inventory and billing systems stay in sync
This balance is also highlighted in our post on Enterprise Artificial Intelligence Platforms.
How Cloud Platforms Are Blurring the Line Between Lakes and Warehouses
Not long ago, data lakes and data warehouses lived in separate worlds. Lakes handled unstructured, exploratory workloads, while warehouses were built for structured business reporting. Enter cloud-native platforms, which have rewritten this narrative.
Today, platforms like Snowflake, Databricks Lakehouse, and Google BigQuery are closing the gap between lakes and warehouses by bringing in the best of both worlds into a single environment. They can handle structured, semi-structured, and unstructured data while offering pay-as-you-go storage, elastic compute, and virtually unlimited scalability.
How the Boundaries Are Fading
- Scalable Architecture: Cloud platforms separate compute and storage with lake-like flexibility at warehouse-scale performance.
- Cross-Source Querying: Engines like BigQuery and Redshift Spectrum let you query raw (lake) data and curated (warehouse) data at the same time.
- Unified Governance: Functionality such as Snowflake’s sharing and Databricks’ Unity Catalog provides assurance for raw data as well as structured data.
These platforms deal with the challenge of storage or computing, but they do not deal with the problem of application fragmentation.
The valuable data from sources like Salesforce, NetSuite, QuickBooks, or ServiceNow remains siloed till it is brought together. And that’s where integration again comes into the picture, and iPaaS solutions such as DBSync step in. They help by connecting disparate systems, bridging cloud-native platforms, and keeping pipelines running smoothly as the number of sources or applications expands. And whether you are exploring data lakes, scaling with warehouses, or managing both, DBSync makes sure that your data flows to the right place at the right time and ensures you keep your momentum.
In short, cloud-native platforms are blurring the lake-warehouse boundaries, but integration is the adhesive that makes this convergence valuable to achieve tangible business results.
Future Outlook: From Debate to Convergence
Here is the most distinct point of view: the argument itself is fading. The future isn’t data warehouse vs. data lake; rather, it is the data fabric where both exist side by side, tied together with real-time integration and governed by business rules.
We are going forward to the future where:
- The data lakes and data warehouses are just layers among the larger ecosystem.
- Integration platforms automate pipelines, helping provide insights and decisions in real-time, whether data lands raw or polished.
- AI agents not only consume data but also optimise the way it is routed, governed, and transformed.
The true future competitive advantage isn’t owning the lake or warehouse, but it’s about orchestrating the flow between them.
Conclusion: Building a Data Journe
The argument between data warehouses and data lakes is less about choosing sides and more about where your data future is.
- Data lakes maximize flexibility
- Data warehouses maximize trust
- Convergence allows you not to sacrifice one for the other
- Integration ensures that the entire structure works in harmony
Now that we have explored the land of data lakes vs data warehouses through a new lens, instead of asking, ‘Which option should we pick?’ Ask, ‘Where are we headed, how quickly do we need to get there, and how can we keep that momentum going?’
With the rise of data fabrics and lakehouses, organisations need not treat lakes and warehouses as competing choices. Instead, they can evolve toward a converged approach where raw flexibility, structured reliability, and continuous integration all coexist.
And with the right integration backbone, your data doesn’t just sit in storage. It transforms into a living asset that actively and continuously drives business growth